Location
Stanford, CA
“Racial Disparities in Automated Speech Recognition” is a report that analyzed how accurately automated speech recognition systems (ASRs) interpret audio by white and Black speakers. In 2019, the project investigated the leading speech-to-text systems built by Amazon, Apple, Google, IBM, and Microsoft. The researchers fed thousands of audio samples from 42 white and 73 Black men and women and analyzed resulting error rates. The paper found significant disparities by race that were compounded by gender. Furthermore, the report revealed that the technology tested performed far worse for speakers who used more linguistic features characteristic of African American Vernacular English. The disparities were consistent across all five firms studied.
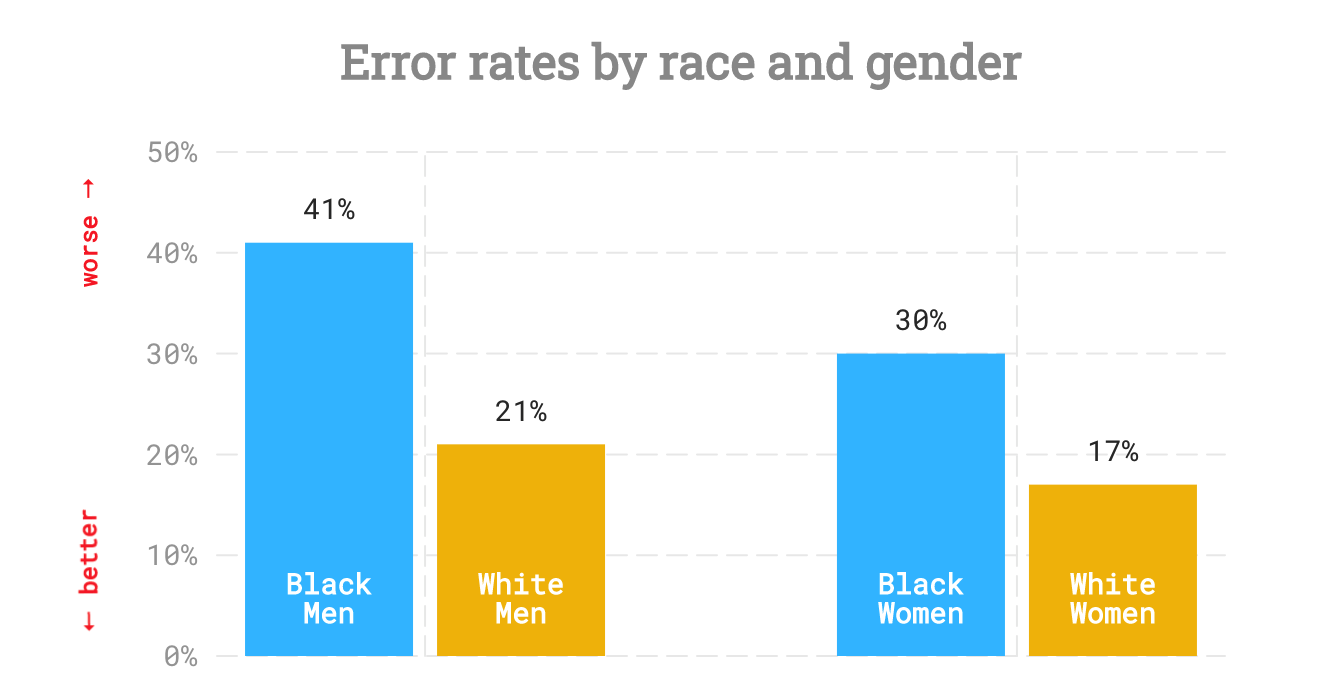 The report found that error rates in ASRs for Black speakers nearly double those for white speakers.
The report found that error rates in ASRs for Black speakers nearly double those for white speakers.
AI is rapidly moving into everyday life and influencing decision making in various industries such as healthcare and law enforcement. However, as summarized in “Racial Disparities in Automated Speech Recognition,” researchers have uncovered that applications in machine learning suffer from racial bias in many facets of automation. Those groundbreaking studies consistently revealed that the underlying machine learning technology is based on incomplete and unrepresentative datasets. In the case of ASR systems, “Racial Disparities in Automated Speech Recognition” concluded that machine learning technology underlying speech recognition systems likely relies too heavily on audio samples of white Americans.”1
ASR technology can benefit everyone and range from everyday convenience to life-changing aids. Unfortunately, at present, not everyone can equally take advantage of these powerful new tools.
 To ensure that ASR technology is inclusive and available to all users, it is critical that academic researchers and industry professionals develop more diverse datasets.
To ensure that ASR technology is inclusive and available to all users, it is critical that academic researchers and industry professionals develop more diverse datasets.
“Racial Disparities in Automated Speech Recognition” was authored by researchers affiliated with the Stanford Computational Policy Lab. The report was published in the Proceedings of the National Academies of Sciences of the United States of America.
The report demonstrated that for every hundred words spoken, the systems studied made 19 errors for white speakers compared to 35 errors for Black speakers. The word error rates were worst for Black men. For every hundred words spoken, the systems studied made 41 errors for Black men, 21 errors for white men, 30 errors for Black women, and 17 errors for white women.
The report concludes that closing the ASR performance gap will require datasets that reflect the full diversity of accents and dialects of all Americans. Furthermore, the researchers assert that speech recognition tools should be regularly assessed and academia/industry should publicly report progress in making ASRs more broadly inclusive.
“Racial Disparities in Automated Speech Recognition” received significant media attention. The report was mentioned in 44 news stories by 36 news outlets including The New York Times, Brookings, Medium, World Economic Forum, Forbes, Scientific American, and more. The paper scored in the top 5% of all research ever tracked by Almetric, a measurement of research impact online that has tracked over 32.1million research outputs.
The report is the basis of the Stanford Computation Policy Lab’s Fair Speech project2, which currently hosts an interactive piece of journalism on racial disparities in ASR. “Racial Disparities in Automated Speech Recognition” also inspired “Voicing Erasure,3” a moving recorded poem produced by the Algorithmic Justice League featuring leading scholars on race, gender, and technology. Additionally, the research team continues to advise and help the groups that reach out to them in regard to how ASR systems can be adjusted to account for the discrepancies identified in this report.
In the future, the report’s lead author, Allison Koenecke, would like to see more research on disparities in automation in other domains of technology.
¹ Allison Koenecke et al., “Racial Disparities in Automated Speech Recognition,” Proceedings of the National Academy of Sciences 117, no. 14 (April 7, 2020): 7684–89. ↩
² Sharad Goel et al., “The Race Gap in Speech Recognition,” accessed April 23, 2021, https://fairspeech.stanford.edu. ↩
³ Joy Buolamwini, Voicing Erasure - A Spoken Word Piece Exploring Bias in Voice Recognition Technology, 2020, https://www.youtube.com/watch?v=SdCPbyDJtK0. ↩